

This page briefly introduces some of our research themes. Of course, we are working on other research topics related to image processing widely.
Development of computer-aided lesion diagnosis system using image processing and machine learning
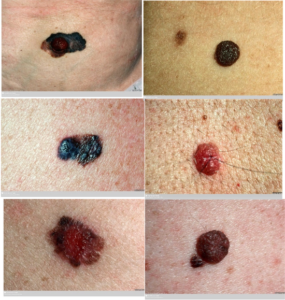
The left images show examples of melanoma (malignant), a type of skin cancer. On the other hand, the right ones are normal bruises, a benign image not related to any disease. These images look quite similar, but in this research, we are trying to find a way to correctly distinguish malignant from benign by applying machine learning method.
More specifically, we aim to let computers (rather than humans) decide the criteria for the problem of “what image features are useful for distinguishing benign from malignant” using machine learning. And also we are working on the problem of “What processing procedure is established to efficiently extract these image features”. Ultimately, our goal is to develop a supporting system that can tell us “there is XX% probability that this image is melanoma” just by inputting an image of the affected area. In other words, our goal is to develop a system that can support the diagnosis of medical specialists and help in the early detection of lesions.

In addition, the framework to be established in this research, i.e., “segment the lesion from the image → extract and represent the features of the lesion → select effective feature groups based on machine learning → predictive diagnose based on those features,” can be directly applied to other lesions. In other words, if it is relatively easy to capture the affected area (not at the cellular level, but at the tissue level) as an image , it may be possible to easily implement a similar diagnosis supporting system. As an example, our group is working on the early prediction of cervical cancer using macroscopic images.
3D reconstruction from single- or multiple-viewpoint images
3D reconstruction from videos captured using unmanned aerial vehicles such as drone
There have been many research related to 3D reconstruction from 2D images taken from multiple viewpoints, which is called stereo method, in all over the world. In particular, our group is challenging the problem of recovering the shape structure of rice plants from aerial images taken by a drone. Not only for rice, but also for such as leaves and stems, image features such as SIFT and ORB are difficult to extract, and the reconstructed 3D points become extremely sparse. In this research, we are developing an algorithm to estimate vegetation area using RGB color information and to only process the area intensively, and also developing an efficient method to obtain more feature points.
If rice shape can be reconstructed accurately, it will be possible to measure and analyze parameters directly related to yield, such as the number of ears and grains per plant, from the reconstructed model. These are tasks that have traditionally been carried out manually, so the completion and realization of this research is expected to greatly reduce labor and improve efficiency.

Point correspondence estimation with less wrong pairs between different viewpoint images using time series images
The key technology to 3D reconstruction based on stereo method is “how to estimate correct point correspondence between different viewpoint images”. If this is solved well, the accuracy of final 3D reconstructed model can be improved. On the other hand, if correspondences are estimated with many errors, reconstructed 3D information becomes unreliable.
Therefore, our group is studying techniques to determine point correspondences between images with as few errors as possible. For example, if we use videos taken by a drone, we can easily obtain time-series images (a group of multiple images whose order is determined by the time axis), and we can calculate “optical flow” from those images and can use it as additional information. The figure below shows a point correspondence estimation example where wrong correspondences are suppressed by using optical flow.


Sequential estimation of a spatial plane in a single viewpoint image
There are some problems with the stereo method, such as “the time and effort required for camera calibration” and “the method cannot be applied if two (or more) images with different viewpoints cannot be prepared”. For example, stereo method cannot be used for a part of fixed viewpoint video taken by such as surveillance cameras or for old photos in past documents, because they cannot be retaken from different viewpoint.
Therefore, we are studying techniques to estimate 3D information such as height or planar structure of object and distance between arbitrary points, from only a single viewpoint image. In particular, we are developing algorithms for sequentially estimating the plane (3D parameters) in an image from only a few cues. Our main research interest is to find out what kind of 3D parameters can be estimated by using what kind of cues.
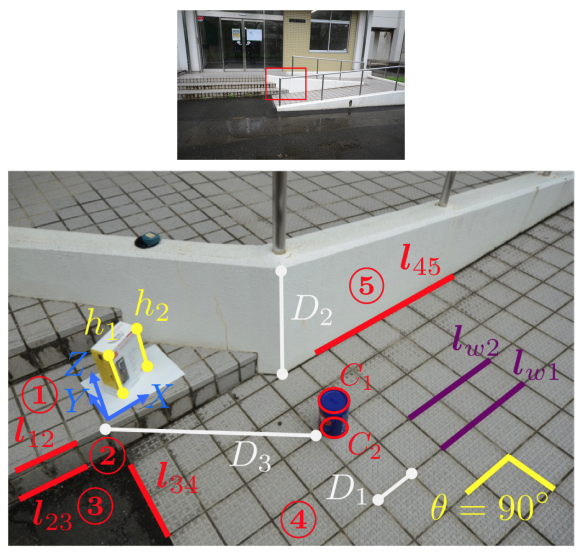
(Estimate plane ① from the actual height information of \(h_1, h_2\), etc. → Estimate plane ② from the intersection line \(l_{12}\) between the planes → Estimate plane ③ from the intersection line \(l_{23}\) → …. Like this, using various cues obtained from the real scene, the neighboring planes can be estimated sequentially. Once the planes ① to ⑤ are determined, the actual 3D distances such as \(D_1\sim D_3\) can be estimated with just a single viewpoint image.)
Development of image processing technology to support visually impaired people

The main purpose of this research is to develop a pedestrian supporting system for visually impaired people using image recognition technology. For example, in developing countries such as Mongolia, infrastructure such as sidewalks is still poorly developed unlike developed countries such as Japan. In particular, there are many places where the sidewalk is kept under construction, the pedestrian guide blocks are broken and curve abruptly. This makes it extremely dangerous for visually impaired to walk around alone, and there is a great need for some kind of countermeasures.
In this research, we are developing a support system that can estimate and detect dangerous objects and locations in the images acquired from a small camera or a smartphone attached to a pedestrian and can alert with sound. In the future, we aim to realize a system that can automatically construct safe walking path and effectively present recommended routes to visually impaired by analyzing images more detail.
